cassandra
概念
基础技术
gossip
每个节点根据一个特定的集群状态计算出的某个节点的sharding信息应该是完全一样的。
首先集群中的每个节点获得的集群状态应该是一致的,其次根据这个一致的状态应该用同样的逻辑来进行计算
Gossip协议是一种无中心节点的分布式系统中常用的通信协议,akka等系统也用。简单来说就是每个节点周期性地随机找一个节点互相同步彼此的信息,P2P通信,很像人类社会的“gossip”因而得名。Cassandra为了防止集群被拆成两半,主要通过两个手段。第一个手段是gossip协议需要在起始阶段人工指定“种子节点”来获取初步的信息,并且一般来说需要每个节点填相同的若干个种子节点以保证在初期肯定能连到同一个集群中,此外每个gossip周期随机选其他节点同步消息时,如果随机到的不是种子节点则额外选随机一个种子节点再进行同步。这样既可以保证每个节点都能连到同一个集群中,也可以保证每个已存在的节点可以第一时间知道有新的节点加入(因为种子节点是最先知道新节点加入的)。
总的来说对gossip消息的处理就是在消息中封装自己知道的集群中每个节点的当前状态的version给对方,对方与本地信息判断,如果比本地新就更新本地,如果比本地旧就把更新的信息给对方。
Gossip只维护集群节点状态信息,不负责维护其他信息。
一致性哈希
参考资料
一致性哈希(consistent hashing)是分布式哈希表(distributed hash table)的一种
Kademlia算法的细节可以看维基百科等资料,Kademlia算法解决的是节点数非常多、不能把网络中的每个节点都存起来的情况。
一致性哈希是DHT的另一种算法,把哈希值的取值空间首尾连接变成一个环,每个哈希值在环上都能找到对应的位置,数据的哈希值对应位置顺时针找下一个节点对应的哈希值的位置,就是该存放这条数据的节点(如果数据存N份就是接下来的N个节点)。这种算法的优势是如果环上增减了节点,只需要迁移环上位置上下两侧对应的数据,其他的数据不用动?这会导致数据不均匀。
Cassandra从1.2开始支持虚拟节点vnode——每个Cassandra实例在环上注册多个节点(默认256个)。vnode意味着增加或者减少一个实例的时候,导数据会从几乎所有节点导,而不是只从相邻节点导,在数据总量不变的情况下,从更多的节点导可以减少导数据的时间,也可以均衡负载。
副本同步 Replication
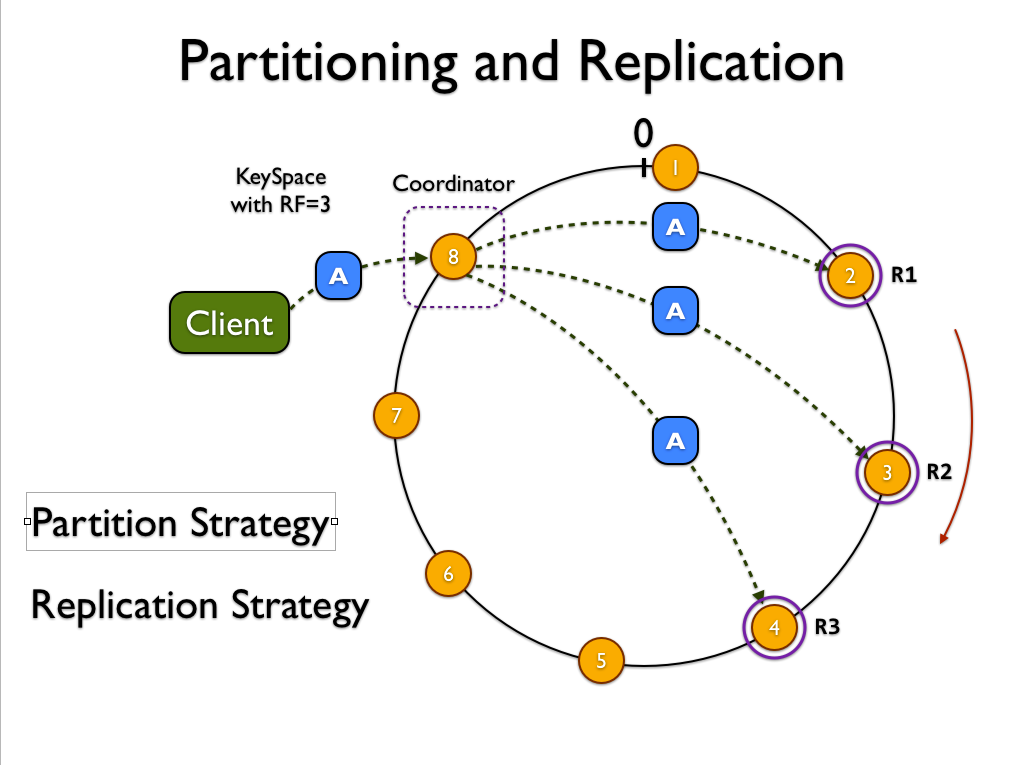
问题
N=3,R=W=2 因为为了确保可用性,通常读写时W和R都会小于N,因此通常N是3然后WR都设为quorum也就是2。不考虑时间戳误差的问题的话基本上是可以确保总是能读到最新的数据的。但是可能很多数据实际上只写了两份,第三份失败了。虽然平时读起来没啥问题,对client来说是感知不到的,无论选哪两个节点读,都还是能读到数据。如果这个时候想新增一个节点,而这个节点在导数据的时候选择从没有数据的那个节点导(为了加快速度减少初期的磁盘冗余Cassandra只会从N个节点中的一个来导某个区间的数据),那么导完数据在status从joining变成up后,可能会出三种问题
第一个问题是,假如新上来的节点在环上取代的那个节点恰好是本来有数据的节点,那么接下来这个数据对应的三个节点里只有一个节点有这个数据,这个时候依然quorum的读就有1/3的概率读不到数据了不符合预期,而且数据冗余只有1份也很容易彻底丢失。
第二个问题是,导数据的时候新写的数据还是写在原来的那三个节点,假设依然是有一个节点没写成,那么导完数据节点变成up后,还是有可能只有一个节点有数据。
第三个问题是,因为gossip的集群信息维护是最终一致性的,一个节点从joining变成up并不是马上就让所有人知道的,一旦有些client知道有些client不知道,那么读写的节点就只有两个是一样的第三个是错开的,假如写的client又是只写成两份,与他错开的client可能就只能读到一份了。
这三个问题总体上都是因为quorum的写并不能保证所有节点都写成功,而降低冗余度无论对数据安全性还是一致性都没好处。因此Cassandra提供两种方式来修复冗余度。第一种是在读取的时候进行read repair操作,强制从所有节点读数据,一旦发现数据不一致就将N个数据合并作为真正的最新数据,把最新数据与每个节点当前数据diff的部分重新写回去。第二种是后台的repair操作,一次repair一个表在当前节点的所有数据。
对第二个问题和第三个问题为了避免不得不开read repair,Cassandra有个特殊处理,如果发现当前写入的数据想写W份而目前正有一个节点在导数据而未来这个数据也会放在这个新节点上,那么就把这个新节点也当做写入的目标,并且必须额外再多写成功一份才算全局成功,也就是从四个节点里写成三个才可以。这样就不用开read repair了。
compaction
Cassandra现在提供三种compaction的策略。Size-tiered、Leveled、Date-tiered。Size就是把大小相近的SSTable合成大的,是最常用的;Leveled就是跟leveldb一样,适合读>>写而且插入多于修改和删除的;Date-tiered是最近刚加的,适合类似发微博之类的对每个partition key插入的column key永远单增(比如当前时间戳)而且不修改旧数据的。第三个没用过,只有一个表用过leveled,是词典的发音数据。词典发音数据是一堆真人发音+例句的TTS发音文件,当数据库没有数据的时候,去请求TTS服务器来合成语音并存入Cassandra,所以这个表的写入量非常小,几乎没有,因此很适合leveled compaction。除了这个表还用了另一个表存“海量发音”,就是词典去年新出的能看一个词全世界各国人民的当地发音的数据,这个表只用了Size-tiered,因为要不断从合作方抓数据,更新的频率比前一个表大不少。对比来看的话,使用leveled compaction的表的平均读取延迟少了一半。
删除产生tombstone
LSM类的数据库都是把删除替换为写入一个标记,叫tombstone。HBase也差不多的原理,删除数据的话把tombstone写到log里,compaction的时候如果遇到tombstone就可以不用保留已经被删的数据,读数据的时候遇到tombstone就屏蔽掉数据并且跳过,最后返回所有没删的数据。但是,C*因为并不是靠单个region server来读写数据,而是N个节点同时读写,所以跟HBase最大的区别,就是每个节点维护tombstone的时候不能只考虑自己。于是某单个节点读数据的时候读到tombstone后,不能屏蔽掉data然后跳过,而是要把tombstone也返回给接受client请求的那个coordinator,因为你不知道其他节点是否写入了这个tombstone(因为写入W个就算成功)。而且在compaction的时候不能判断说当前节点跟这个tombstone有关的数据都删完了就把自己也删了,因为你不确定别的节点有没有这个tombstone——如果别的节点在写tombstone的时候没写成(毕竟写W个节点就算成功,最多N-W个节点没有这个tombstone),自己又在compaction的时候把tombstone删了,那么再读数据的时候有节点有这行数据,又没有节点有这行数据的tombstone,于是这个数据就复活了。
Cassandra通过写一条“tombstone”来标记一个数据被删除了。被标记的数据默认要10天(配置文件中的gc_grace_seconds)后且被compaction或cleanup执行到对应的SSTable时才会被真正从磁盘删除,因为如果当时这个delete操作只在3个节点中的2个执行成功,那么一旦2个有tombstone的节点把数据删了,集群上只剩下没tombstone的那个节点,下次读这个key的时候就又返回对应的数据,从而导致被删除的数据复活。Repair操作可以同步所有节点的数据从而保证tombstone在3个节点中都存在,因此如果想确保删除100%成功不会复活需要以小于gc_grace_seconds的周期定期执行repair操作(所以官方建议”weekly”)。
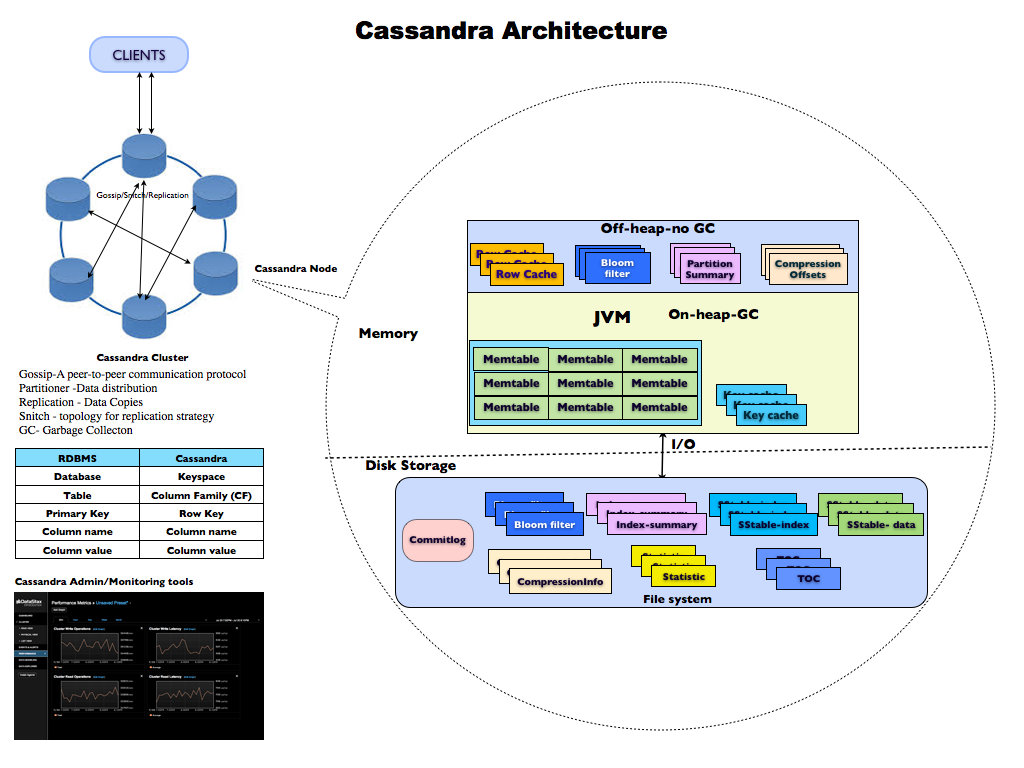
架构