kafka
角色
- producer
- consumer
- broker 多个partition分布在多个broker上
- partition
一个partition存在所有的副本上
示例为2个副本,4个partition,4个broker
示例为2个副本,6个partition,6个broker
replication 一个副本有所有的partition
- 副本分配逻辑规则如下: 在Kafka集群中,每个Broker都有均等分配Partition的Leader机会。 上述图Broker Partition中,箭头指向为副本,以Partition-0为例:broker1中parition-0为Leader,Broker2中Partition-0为副本。 上述图种每个Broker(按照BrokerId有序)依次分配主Partition,下一个Broker为副本,如此循环迭代分配,多副本都遵循此规则。
- 副本分配算法如下: 将所有N Broker和待分配的i个Partition排序. 将第i个Partition分配到第(i mod n)个Broker上. 将第i个Partition的第j个副本分配到第((i + j) mod n)个Broker上.
topic 对应多个partition
offset
leader
- ISR

副本同步
Producer在发布消息到某个Partition时,先通过Zookeeper找到该Partition的Leader, 然后无论该Topic的Replication Factor为多少(也即该Partition有多少个Replica), Producer只将该消息发送到该Partition的Leader。
Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。这种方式上,Follower存储的数据顺序与Leader保持一致。Follower在收到该消息并写入其Log后,向Leader发送ACK。为了性能考虑,每个follower当消息被写到内存时就发送ack(而不是要完全地刷写到磁盘上才ack). 一旦Leader收到了ISR中的所有Replica的ACK,该消息就被认为已经commit了,Leader将增加HW并且向Producer发送ACK。为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。但考虑到这种场景非常少见,可以认为这种方式在性能和数据持久化上做了一个比较好的平衡。在将来的版本中,Kafka会考虑提供更高的持久性。 Consumer读消息也是从Leader读取,只有被commit过的消息(offset低于HW的消息)才会暴露给Consumer。Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的Follower都复制完,这条消息才会被认为commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,Follower异步的从Leader复制数据,数据只要被Leader写入log就被认为已经commit,这种情况下如果Follower都复制完都落后于Leader,而如果Leader突然宕机,则会丢失数据。而Kafka的这种使用ISR的方式则很好的均衡了确保数据不丢失以及吞吐率。Follower可以批量的从Leader复制数据,这样极大的提高复制性能(批量写磁盘),极大减少了Follower与Leader的差距。
为了简单起见,只有leader可以提供读消息的服务.并且最多只到hw位置的消息才会暴露给客户端.
ISR
如果失败的follower恢复过来,它首先将自己的日志截断到上次checkpointed时刻的HW.
架构
producer-consumer-cluster
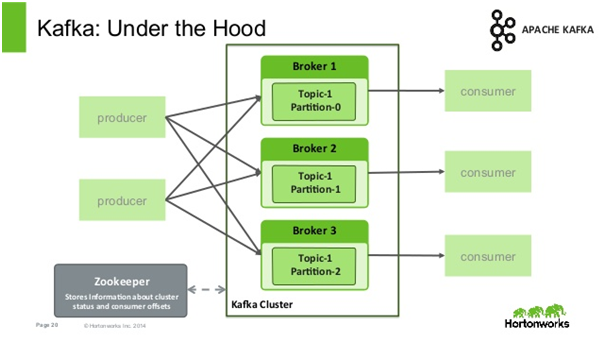
broker

replication


总结
- Partition副本由Leader和follower组成,只有ISR列表中的副本是仅仅跟着Leader的
- Leader管理了ISR列表,只有ISR列表中的所有副本都复制了消息,才能认为这条消息是提交的
- Leader和follower副本都叫做Replica,同一个Partition的不同副本分布在不同Broker上
- Replica很重要的两个信息是HighWatermark(HW)和LogEndOffset(LEO)
- 只有Leader Partition负责客户端的读写,follower从Leader同步数据。类似mongodb
- 所有Replica都会对HW做checkpoint,Leader会在follower的拉取请求时广播HW给follower