redis
源码剖析
redis设计与实现
nosqlfans系列文章
Redis 的源码只有2万来行,个人觉得是一个非常合适的学习Unix 环境下C语言编程的实例教材。而读源码,也对了解Redis内部结构很有帮助。
下面推荐的几篇文章,来自阿里巴巴云计算运维部的 hoterran 同学的个人博客,分别对Redis几个重要流程的源码进行了分析研究,对了解Redis内部结构很有帮助。
1.REDIS源代码分析 – HASH TABLE
Redis的Hash Table 在源码里对应的是其dict结构(字典结构),本文内容介绍了Redis 在hash table的结构,产生hash冲突的解决方法,以及非常Redis非常重要的rehash操作过程。
2.REDIS源代码分析 – EVENT LIBRARY
本篇文章主要介绍了Redis的异步网络事件驱动库,主要介绍了Redis使用它来实现非阻塞的网络事件处理的过程。包括了采用此库实现的Redis中各种定时器的原理。
3.REDIS源代码分析- REPLICATION
本文介绍了Redis的主从同步策略及原理,介绍了Redis在主从同步时的一些内部命令和内部状态切换。
4.REDIS源代码分析 – PERSISTENCE
此文介绍了Redis的 dump.rdb 定时镜像及 aof 日志型备份的实现原理。
5.REDIS源代码分析 – PROTOCOL
本文介绍了Redis在处理网络请求的过程中对Redis协议的分析,介绍了Redis Client对象对客户端命令的解析过程及处理流程。
Redis核心解读系列
Redis是知名的键值数据库,它广泛用于缓存系统。关于Redis的信息已经不用我多介绍了。这个系统的Redis文章主要从另外一个角度关注,Redis作为一个开源项目,短短2W行代码包含了一个健壮的服务器端软件的必需,我们从Redis中可以学习C语言项目的编程风格、范式,学习类Unix下的系统编程,还有对于一个常驻服务的健壮性考虑等等。
对于一个C语言的初学者来说,学习一个类似Redis这样不大不小的项目是非常好的选择。Redis既没有Nginx深入性能细节的晦涩编码方式,又具备了一个性能敏感应用的C项目编程方式,是一个非常适合入门的项目。
Redis核心解读系统来自于本人对于Redis的学习和总结,不同于Redis 设计与实现(对于这本书的作者表示非常佩服,能写出如此漂亮,详细的Redis解读)这个Redis代码注释方式 详细解读,本系列主要是选取精彩代码和关键路径进行解读,带领进入Redis的核心内容。并且会着重介绍Redis实现上的Hack写法。另外,本人对于Redis的某些设计也有独特见解,特别是对Redis的集群分发管理上,见相关文章。
Redis核心解读系列主要有以下内容:
解读ae事件驱动库
解读Redis中ziplist、zipmap、intset实现细节
解读Redis运行核心循环过程
Redis核心解读-从Master到Slave的Replicantion
Redis核心解读–类型系统解构
Redis核心解读–数据持久化过程与RDB文件
Redis核心解读–AOF与REWRITE机制
Redis核心解读–Slow Log
Redis核心解读–事务(Multi和CAS)的实现
Redis核心解读–pubsub(发布者-订阅者模式)的实现
Redis核心解读–集群管理工具(Redis-sentinel)
核心数据结构
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
struct dictEntry *next;
} dictEntry;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size; //dictEntry数组大小
unsigned long sizemask;
unsigned long used; //所有元素的数量,包含链表元素
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
cluster
Compared with Twemproxy and Redis Cluster
| Codis | Twemproxy | Redis Cluster | |
|---|---|---|---|
| resharding without restarting cluster | Yes | No | Yes |
| pipeline | Yes | Yes | No |
| hash tags for multi-key operations | Yes | Yes | Yes |
| multi-key operations while resharding | Yes | - | No(details) |
| Redis clients supporting | Any clients | Any clients | Clients have to support cluster protocol |
Twemproxy
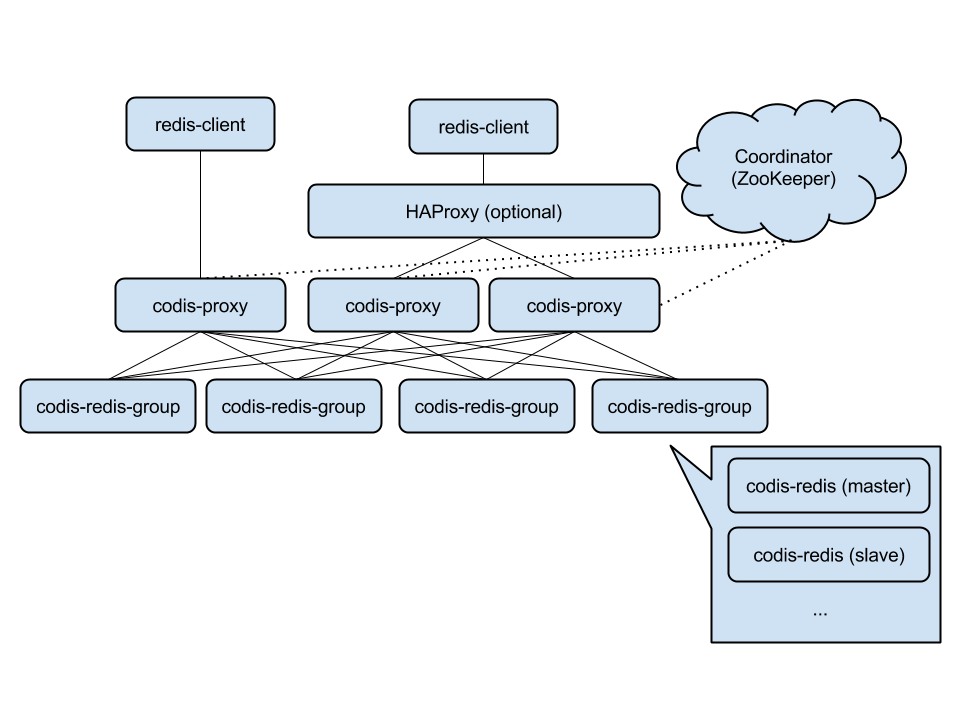
codis
architecture
redis cluster
Redis Cluster原理
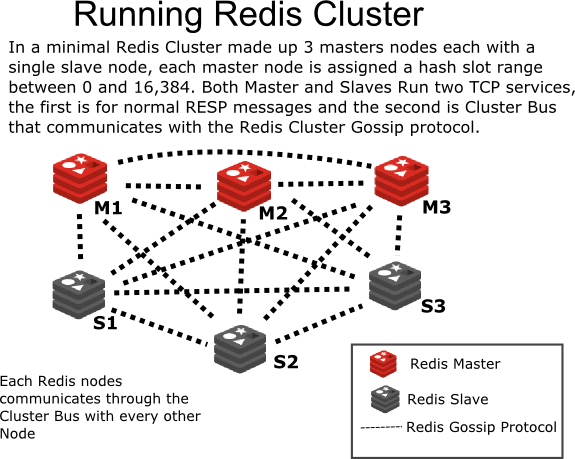
Redis Cluster 是Redis的集群实现,内置数据自动分片机制,集群内部将所有的key映射到16384个Slot中,集群中的每个Redis Instance负责其中的一部分的Slot的读写。集群客户端连接集群中任一Redis Instance即可发送命令,当Redis Instance收到自己不负责的Slot的请求时,会将负责请求Key所在Slot的Redis Instance地址返回给客户端,客户端收到后自动将原请求重新发往这个地址,对外部透明。一个Key到底属于哪个Slot由crc16(key) % 16384 决定。
关于负载均衡,集群的Redis Instance之间可以迁移数据,以Slot为单位,但不是自动的,需要外部命令触发。
关于集群成员管理,集群的节点(Redis Instance)和节点之间两两定期交换集群内节点信息并且更新,从发送节点的角度看,这些信息包括:集群内有哪些节点,IP和PORT是什么,节点名字是什么,节点的状态(比如OK,PFAIL,FAIL,后面详述)是什么,包括节点角色(master 或者 slave)等。
关于可用性,集群由N组主从Redis Instance组成。主可以没有从,但是没有从 意味着主宕机后主负责的Slot读写服务不可用。一个主可以有多个从,主宕机时,某个从会被提升为主,具体哪个从被提升为主,协议类似于Raft,参见这里。如何检测主宕机?Redis Cluster采用quorum+心跳的机制。从节点的角度看,节点会定期给其他所有的节点发送Ping,cluster-node-timeout(可配置,秒级)时间内没有收到对方的回复,则单方面认为对端节点宕机,将该节点标为PFAIL状态。通过节点之间交换信息收集到quorum个节点都认为这个节点为PFAIL,则将该节点标记为FAIL,并且将其发送给其他所有节点,其他所有节点收到后立即认为该节点宕机。从这里可以看出,主宕机后,至少cluster-node-timeout时间内该主所负责的Slot的读写服务不可用。
redis cluster turorial
Redis Cluster supports multiple key operations as long as all the keys involved into a single command execution (or whole transaction, or Lua script execution) all belong to the same hash slot. The user can force multiple keys to be part of the same hash slot by using a concept called hash tags.
Redis Cluster does not use consistent hashing, but a different form of sharding where every key is conceptually part of what we call an hash slot.可以对比一下一致性哈希,确实不完全一样 There are 16384 hash slots in Redis Cluster, and to compute what is the hash slot of a given key, we simply take the CRC16 of the key modulo 16384.
Every node in a Redis Cluster is responsible for a subset of the hash slots, so for example you may have a cluster with 3 nodes, where:
Node A contains hash slots from 0 to 5500. Node B contains hash slots from 5501 to 11000. Node C contains hash slots from 11001 to 16383.
redis cluster spec
Implemented subset
Redis Cluster implements all the single key commands available in the non-distributed version of Redis. Commands performing complex multi-key operations like Set type unions or intersections are implemented as well as long as the keys all belong to the same node.
Redis Cluster implements a concept called hash tags that can be used in order to force certain keys to be stored in the same node. However during manual reshardings, multi-key operations may become unavailable for some time while single key operations are always available.
Redis Cluster does not support multiple databases like the stand alone version of Redis. There is just database 0 and the SELECT command is not allowed.
write safety 数据丢失的可能性
- A write may reach a master, but while the master may be able to reply to the client, the write may not be propagated to slaves via the asynchronous replication used between master and slave nodes. If the master dies without the write reaching the slaves, the write is lost forever if the master is unreachable for a long enough period that one of its slaves is promoted. This is usually hard to observe in the case of a total, sudden failure of a master node since masters try to reply to clients (with the acknowledge of the write) and slaves (propagating the write) at about the same time. However it is a real world failure mode.异步方式同步还是不可靠,应该参考kafka
- Another theoretically possible failure mode where writes are lost is the following:
- A master is unreachable because of a partition.
- It gets failed over by one of its slaves.
- After some time it may be reachable again.
- A client with an out-of-date routing table may write to the old master before it is converted into a slave (of the new master) by the cluster.客户端不知道这时这台机器已经是slave还以为他是master去写,而且写成功了。